Notes app — Modelar datos en MongoDB: SQL vs NoSQL
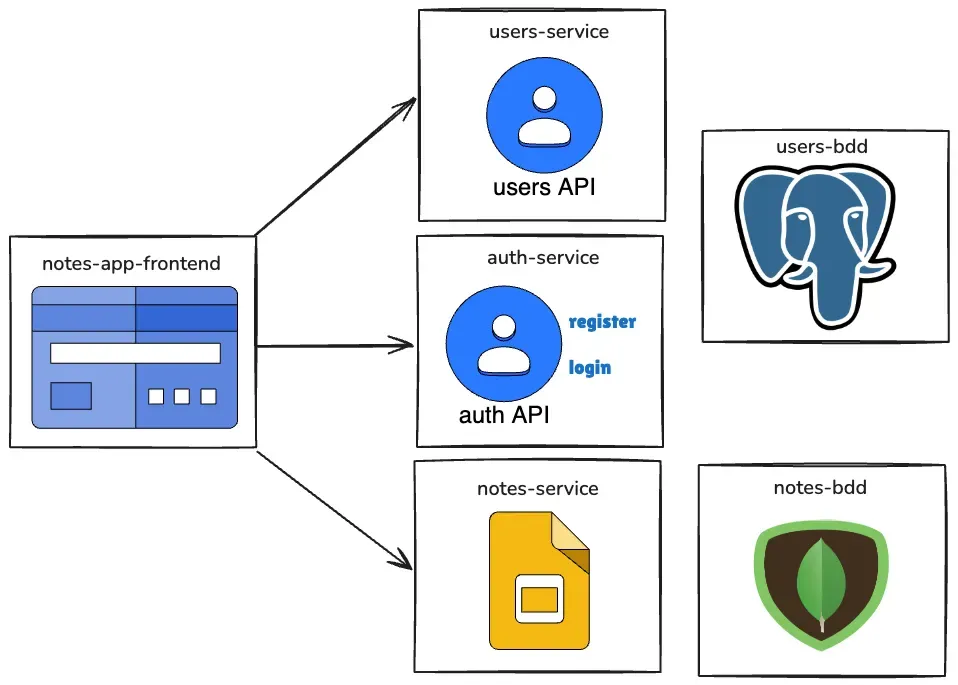
En el desarrollo de software se habla constantemente de los microservicios. Engloban muchísimos conceptos interesantes y hay dos que considero fundamentales para afrontar distintos problemas:
- Uso de bases de datos diferentes en cada microservicio: relacionales vs no relacionales.
- Comunicación entre microservicios.
En este artículo me centro en el primero.
Normalización de bases de datos
Para introducir el concepto, y teniendo en cuenta que hablaremos de normalización y desnormalización, me parece relevante conocer qué se considera una base de datos normalizada.
Base de datos normalizada: aquella que cumple ciertas formas normales, diseñadas para reducir la redundancia de datos y mejorar la integridad de la información. La forma normal más comúnmente aplicada es la Tercera Forma Normal (3NF), que busca eliminar las dependencias transitivas entre los atributos no clave.
Una base de datos en 3NF debe cumplir los siguientes criterios:
- Estar en Primera Forma Normal (1NF): cada columna debe contener valores atómicos (indivisibles) y no debe haber grupos repetitivos.
- Estar en Segunda Forma Normal (2NF): cumplir con 1NF y que todos los atributos no clave dependan completamente de la clave primaria.
- No tener dependencias transitivas: ningún atributo no clave debe depender de otro atributo no clave.
La normalización en 3NF ayuda a:
- Reducir la redundancia de datos.
- Minimizar problemas de actualización.
- Facilitar el mantenimiento de la integridad de los datos.
Más adelante veremos los pros y contras de no seguir estos principios y tener una base de datos desnormalizada.
Uso de bases de datos no relacionales
Al considerar el uso de una base de datos no relacional, la pregunta inicial que surge es: ¿por qué elegir esta opción? En mi investigación sobre el origen de las bases de datos NoSQL encontré varios artículos que explican su historia y los problemas que buscan resolver. Dos factores destacan como principales motivadores: el rendimiento y la flexibilidad.
La teoría suena bien, pero ¿qué implica esto en la práctica del desarrollo? Consideremos un aspecto clave:
Modelado de datos: en lugar de establecer relaciones mediante joins (como en las bases de datos relacionales), en NoSQL se suele optar por desnormalizar los datos. Esto implica añadir claves como referencias directas entre documentos o entidades, lo que puede mejorar significativamente el rendimiento en las operaciones de lectura. Veámoslo con un ejemplo.
Caso: tenemos usuarios en la base de datos SQL y hay que plantear cómo almacenaremos sus notas. Si lo pensamos en grande, con millones de usuarios accediendo a nuestra aplicación, esta será la base de datos con más concurrencia, por lo que la diseñaremos con MongoDB. A continuación veremos dos formas de plantear el modelo de datos: una desnormalizando datos y otra pensando en la estructura como en SQL.
Pensando en SQL
Si adoptamos un enfoque similar al de una base de datos SQL, podríamos modelar las carpetas y notas de los usuarios así:
@Data
@Builder
@Document(collection = "folders")
public class Folder {
private String folderId;
private String name;
private List<Note> notes; // Relación 1 a N: una carpeta contiene muchas notas
}
@Data
@Builder
@Document(collection = "notes")
public class Note {
private Long noteId;
private String title;
private String content;
private List<Reminder> reminders; // Relación 1 a N: una nota puede tener muchos recordatorios
private String createdAt;
private String updatedAt;
}Este diseño refleja un enfoque típico de bases de datos relacionales, donde las relaciones entre entidades (como carpetas y notas) se modelan con claves foráneas y estructuras anidadas. Sin embargo, aplicarlo directamente en MongoDB presenta algunos problemas:
- Límite de tamaño: MongoDB impone un límite de 16MB por documento. Si un documento
Foldercontiene un gran número deNotes, podría alcanzar este límite. - Rendimiento: al cargar un
Folder, MongoDB tendría que cargar todas lasNotesasociadas, lo cual es ineficiente si solo se necesita la información básica delFolder. - Actualizaciones: actualizar una única
Notedentro de unFolderrequiere actualizar todo el documentoFolder, lo que es ineficiente y propenso a errores en aplicaciones con alta concurrencia.
Pensando en NoSQL
Ahora, si modelamos teniendo en cuenta las características de una base de datos NoSQL como MongoDB, podríamos diseñarla así:
@Data
@Builder
@Document(collection = "folders")
public class Folder {
@Id
private String folderId;
private String name;
private String username; // Referencia al usuario propietario de la carpeta
}
@Data
@Builder
@Document(collection = "notes")
public class Note {
@Id
private String noteId;
private String title;
private String content;
private String folderId; // Referencia al Folder al que pertenece
private String username; // Referencia al usuario propietario de la nota
private String createdAt;
private String updatedAt;
}En este diseño desnormalizamos los datos al incluir folderId y username directamente en la colección de notes. Este enfoque tiene varias ventajas en un contexto NoSQL:
- Eliminación de joins: MongoDB no soporta joins de forma nativa como SQL, así que almacenar
folderIdyusernamedirectamente en las notas permite consultas eficientes sin unir documentos. - Escalabilidad y rendimiento: desnormalizar los datos y almacenarlos en documentos separados (carpetas y notas) permite consultas más rápidas, especialmente en operaciones de lectura intensiva.
- Flexibilidad: el modelo es más flexible, ya que permite modificar o escalar cada entidad (carpetas y notas) de forma independiente.
Conclusión
Al diseñar la base de datos de una aplicación de notas en MongoDB hemos explorado cómo el pensamiento NoSQL difiere del enfoque tradicional SQL. Tres aspectos cruciales:
- Desnormalización estratégica: incluir deliberadamente datos redundantes, como el
usernameen varias colecciones, puede mejorar significativamente el rendimiento de las consultas, aunque requiere cuidado para mantener la consistencia. - Modelado orientado a consultas: estructurar los datos pensando en cómo serán consultados, no solo en cómo se almacenarán, fue lo que nos llevó a separar las notas de las carpetas en colecciones distintas.
- Flexibilidad vs. consistencia: MongoDB ofrece gran flexibilidad de esquema, permitiéndonos adaptar fácilmente el modelo de datos, pero también nos exige ser más conscientes en el manejo de la consistencia.
Al final, la elección entre un enfoque relacional y uno NoSQL dependerá de los requisitos del proyecto, los patrones de acceso a datos y las expectativas de crecimiento. Lo importante es entender las implicaciones de cada enfoque y elegir la herramienta adecuada para el trabajo en cuestión.
Al terminar de implementar este microservicio me surgieron varias dudas. Por ejemplo: si elimino un usuario de la base de datos de autenticación, ¿cómo elimino sus notas? Hablaré próximamente de cómo resolver este problema de forma fiable y consistente, con la comunicación asíncrona entre microservicios.
Si quieres ver el progreso del proyecto, puedes acceder al repositorio aquí.